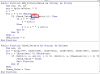
Function TV(ByVal Text As String) As String
On Error Resume Next
Dim CharCode, ResText As String, i As Long, tmp As String
tmp = Text
CharCode = Array(ChrW(7855), ChrW(7857), ChrW(7859), ChrW(7861), ChrW(7863), ChrW(7845), ChrW(7847), _
ChrW(7849), ChrW(7851), ChrW(7853), ChrW(225), ChrW(224), ChrW(7843), ChrW(227), ChrW(7841), _
ChrW(259), ChrW(226), ChrW(273), ChrW(7871), ChrW(7873), ChrW(7875), ChrW(7877), ChrW(7879), _
ChrW(233), ChrW(232), ChrW(7867), ChrW(7869), ChrW(7865), ChrW(234), ChrW(237), ChrW(236), _
ChrW(7881), ChrW(297), ChrW(7883), ChrW(7889), ChrW(7891), ChrW(7893), ChrW(7895), ChrW(7897), _
ChrW(7899), ChrW(7901), ChrW(7903), ChrW(7905), ChrW(7907), ChrW(243), ChrW(242), ChrW(7887), _
ChrW(245), ChrW(7885), ChrW(244), ChrW(417), ChrW(7913), ChrW(7915), ChrW(7917), ChrW(7919), _
ChrW(7921), ChrW(250), ChrW(249), ChrW(7911), ChrW(361), ChrW(7909), ChrW(432), ChrW(253), _
ChrW(7923), ChrW(7927), ChrW(7929), ChrW(7925))
ResText = "aaaaaaaaaaaaaaaaadeeeeeeeeeeeiiiiiooooooooooooooooouuuuuuuuuuuyyyyy"
For i = 0 To UBound(CharCode)
tmp = Replace(tmp, CharCode(i), Mid(ResText, i + 1, 1))
tmp = Replace(tmp, UCase(CharCode(i)), UCase(Mid(ResText, i + 1, 1)))
Next
TV = tmp
End Function